
- Le déploiement du logiciel LAS le 26 octobre 1992 a contribué à 20 à 30 morts supplémentaires parce que le système s'est effondré sous la charge réelle après avoir tenu sous charge de test.
- Il n'existait pas d'environnement de staging équivalent à la production en termes de charge et de volume de données réelles.
- Le plan de rollback vers le système manuel n'était pas formalisé ni testé avant le go-live.
- En Python, un smoke test automatique avant déploiement peut détecter les régressions critiques avant qu'elles atteignent les utilisateurs.
- Le calendrier avait été imposé politiquement et non estimé techniquement, ce qui a compressé les phases de test jusqu'à les rendre inefficaces.
Lecture complète : 13 min
Le 26 octobre 1992, le London Ambulance Service a déployé un nouveau logiciel de dispatch.
Objectif : remplacer un système manuel vieillissant et réduire les temps de réponse. Budget : plusieurs millions de livres sterling. Délai de développement : compressé sous pression politique pour tenir une date annoncée publiquement.
Huit heures après le déploiement, le système a commencé à saturer. Vingt-six heures plus tard, il s’était effondré. Les ambulances ne recevaient plus leurs missions. Des patients attendaient des heures. L’enquête officielle a conclu que le bug avait contribué à 20 à 30 morts supplémentaires pendant la semaine de déploiement.
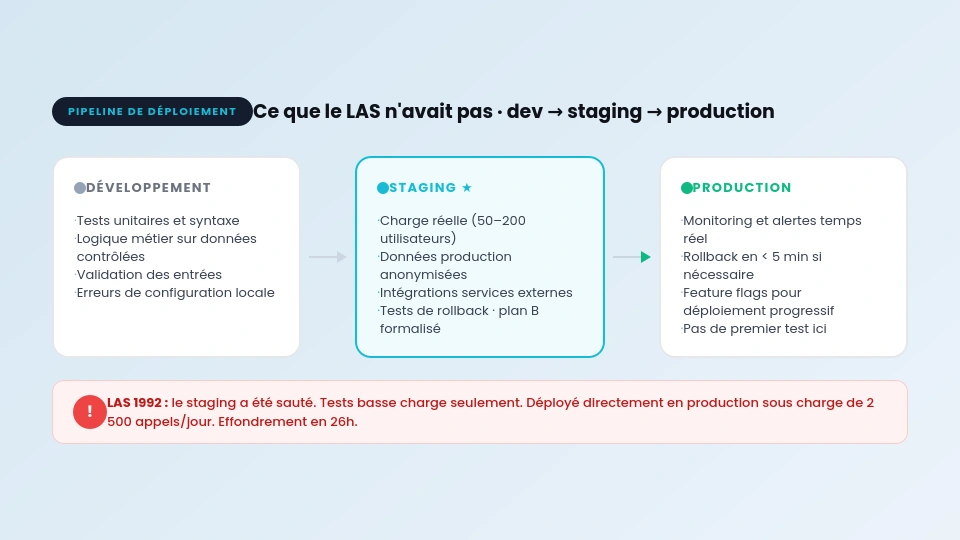
Ce qui distingue le LAS de tous les autres bugs de cette série : il n’y avait pas un seul bug spectaculaire. Il y avait une accumulation de décisions de déploiement incorrectes, dont la principale était l’absence d’environnement de staging.
Ce qui s’est passé le 26 octobre 1992
Le London Ambulance Service gérait environ 2 500 appels par jour en 1992. Son système manuel, basé sur des fiches papier et des opérateurs radio, était lent mais robuste. Le nouveau système informatique était censé automatiser le dispatch, réduire les doublons, et accélérer les réponses.
Le développement avait accumulé plusieurs problèmes :
- Le calendrier avait été imposé politiquement, pas estimé techniquement.
- Les tests avaient été limités à des simulations basse charge sur quelques centaines d’appels simultanés.
- Le personnel opérateur n’avait pas été formé suffisamment sur le nouveau système avant le go-live.
- Il n’y avait pas d’environnement de test équivalent à la production en termes de charge.
- Le plan de retour au système manuel en cas d’échec n’était pas formalisé.
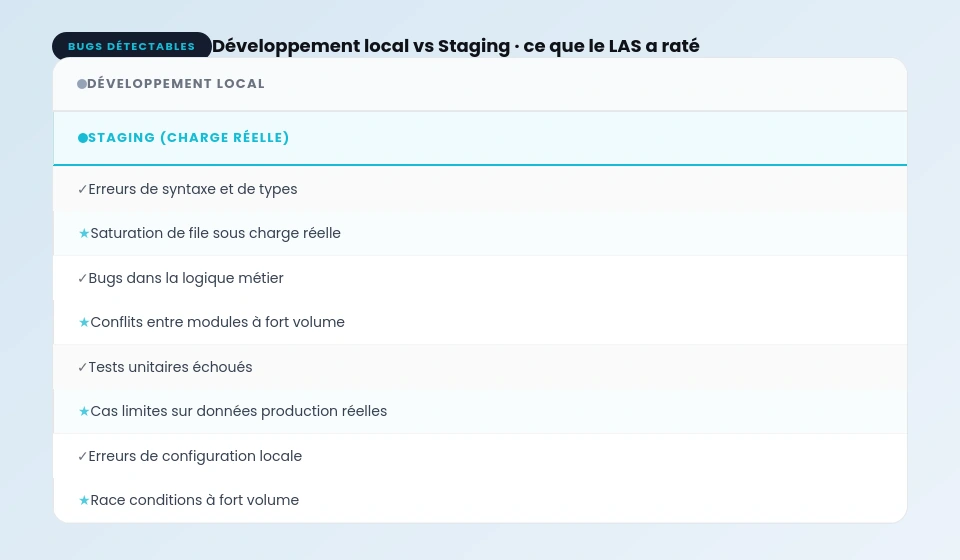
Le 26 octobre, à la mise en service, le système a rencontré des conditions que personne n’avait testées : la charge réelle d’une journée normale de LAS, avec des opérateurs partiellement formés, des données géographiques légèrement différentes des données de test, et des interactions entre modules que les tests unitaires n’avaient pas couvertes.
Le système a commencé à générer des doublons d’appels. Les opérateurs, stressés par l’outil qu’ils ne maîtrisaient pas, saisissaient des informations de correction. Ces corrections créaient de nouveaux doublons. La file de dispatch grossissait plus vite qu’elle n’était traitée. Les ambulances recevaient des missions conflictuelles ou incomplètes.
À 14h, le LAS a tenté de revenir au système manuel. Mais le système manuel avait été partiellement démantelé pour le déploiement. Le retour en arrière a pris des heures.
Le rapport d’enquête Page, publié en 1993, reste l’une des analyses les plus complètes jamais écrites sur un déploiement logiciel catastrophique.
L’anatomie d’un effondrement en production
Ce qui s’est passé au LAS suit un pattern que j’ai vu, à bien plus petite échelle, sur mes propres déploiements.
Le système fonctionne sous charge de test. Il casse sous charge réelle.
La différence entre les deux n’est jamais là où tu l’attends. Ce n’est pas la fonctionnalité principale qui casse. C’est l’interaction entre plusieurs fonctionnalités sous une charge que tu n’as pas testée, avec des données légèrement différentes de tes données de test.
Sur Copyboost, j’ai eu un bug similaire dans sa structure : un module d’analyse qui fonctionnait parfaitement en dev, avec mes propres textes de test, et qui cassait sur certains textes utilisateurs à cause d’un encodage UTF-8 inattendu dans les réponses de l’API. Je ne l’aurais jamais trouvé sans un vrai staging avec de vraies données utilisateurs.
J’en parle dans mon article sur l’automatisation depuis un VPS et les deux bugs qui ont tout cassé.
Le plan de rollback n’existait pas.
Le LAS avait partiellement démantelé son système manuel pour faire place au nouveau. Revenir en arrière était compliqué, lent, et partiel. Quand le déploiement a échoué, il n’y avait pas de position de repli propre.
C’est une erreur que je vois régulièrement dans les projets solo : le rollback est considéré comme un détail à gérer si ça se passe mal, pas comme une condition préalable au déploiement.
Pourquoi le staging environment n’est pas optionnel
Un staging environment est une copie de ton environnement de production, configurée de façon identique mais isolée des vrais utilisateurs. Son rôle est de détecter les bugs qui n’apparaissent qu’en conditions réelles : charge élevée, données de production, interactions entre modules, comportements d’utilisateurs imprévus.
Le staging n’est pas une duplication inutile. C’est la seule façon de tester des conditions que tu ne peux pas simuler localement.
Ce que ton environnement de développement local ne peut pas reproduire :
- La charge simultanée de dizaines ou centaines d’utilisateurs réels.
- Les données de production avec leurs imperfections et cas limites réels.
- Les interactions entre services externes en conditions réelles (APIs tierces, bases de données en production, CDN).
- Les comportements utilisateurs qui dévient des scénarios de test prévus.
- Les problèmes de performance qui n’apparaissent qu’à partir d’un certain volume.
Le LAS n’avait pas de staging qui reproduisait la charge de 2 500 appels par jour. Ses tests couvraient des scénarios basse charge. La différence entre les deux conditions a été fatale.
Ce qu’un staging correct aurait détecté
Voici les types de bugs que le staging du LAS aurait dû capturer.
Bug 1 : saturation de la file de dispatch sous charge élevée
import queue
import threading
import time
def simuler_charge_dispatch(nb_appels_par_minute: int, duree_secondes: int):
"""Simule la charge d'un système de dispatch sous différentes charges."""
file_dispatch = queue.Queue()
appels_traites = 0
appels_en_attente_max = 0
doublons_detectes = 0
appels_vus = set()
def recevoir_appel(id_appel: int):
nonlocal doublons_detectes
if id_appel in appels_vus:
doublons_detectes += 1
return
appels_vus.add(id_appel)
file_dispatch.put({"id": id_appel, "timestamp": time.time()})
def traiter_dispatch():
nonlocal appels_traites, appels_en_attente_max
while True:
taille = file_dispatch.qsize()
appels_en_attente_max = max(appels_en_attente_max, taille)
try:
appel = file_dispatch.get(timeout=0.5)
time.sleep(60 / (nb_appels_par_minute * 0.8))
appels_traites += 1
file_dispatch.task_done()
except queue.Empty:
break
def generer_appels():
intervalle = 60 / nb_appels_par_minute
for i in range(int(nb_appels_par_minute * duree_secondes / 60)):
recevoir_appel(i)
time.sleep(intervalle)
threads = [
threading.Thread(target=generer_appels),
threading.Thread(target=traiter_dispatch),
]
for t in threads:
t.start()
for t in threads:
t.join()
return {
"appels_reçus": len(appels_vus),
"appels_traites": appels_traites,
"file_max": appels_en_attente_max,
"doublons": doublons_detectes,
"saturation": appels_traites < len(appels_vus) * 0.95
}
# Test à charge faible (simulation de test)
print("Charge test (500 appels/min) :")
print(simuler_charge_dispatch(500, 60))
# Test à charge réelle (simulation production)
print("\nCharge production (2500 appels/min) :")
print(simuler_charge_dispatch(2500, 60))Ce test de charge basique aurait montré que le système saturait à partir d’un certain volume. Le LAS n’avait pas ce test.
Construire un staging environment minimal en Python
Un staging professionnel peut coûter cher. Un staging minimal qui capture 80 % des bugs de production coûte quelques heures.
Checklist staging minimal pour un projet Python solo :
# Structure recommandée
mon_projet/
.env.development # Variables locales
.env.staging # Variables staging (données anonymisées)
.env.production # Variables production (jamais commitées)
docker-compose.yml # Dev
docker-compose.staging.yml # Staging# config.py : chargement de la config selon l'environnement
import os
from enum import Enum
class Environnement(Enum):
DEVELOPMENT = "development"
STAGING = "staging"
PRODUCTION = "production"
def charger_config() -> dict:
env = os.getenv("APP_ENV", "development")
try:
environnement = Environnement(env)
except ValueError:
raise ValueError(f"Environnement inconnu : {env}. Valeurs acceptées : {[e.value for e in Environnement]}")
config_base = {
"debug": environnement != Environnement.PRODUCTION,
"log_level": "DEBUG" if environnement == Environnement.DEVELOPMENT else "INFO",
}
if environnement == Environnement.STAGING:
config_base.update({
"db_url": os.getenv("STAGING_DB_URL"),
"api_key": os.getenv("STAGING_API_KEY"),
"rate_limit": 100,
})
elif environnement == Environnement.PRODUCTION:
config_base.update({
"db_url": os.getenv("PROD_DB_URL"),
"api_key": os.getenv("PROD_API_KEY"),
"rate_limit": 1000,
})
return config_base# tests/test_staging.py : tests spécifiques au staging
import pytest
import os
@pytest.mark.skipif(
os.getenv("APP_ENV") != "staging",
reason="Tests de charge uniquement en staging"
)
def test_charge_50_utilisateurs_simultanes():
"""Ce test ne tourne qu'en staging, jamais en dev ni en prod."""
from concurrent.futures import ThreadPoolExecutor
from mon_app import traiter_requete
erreurs = []
def requete_utilisateur(user_id: int):
try:
resultat = traiter_requete(f"user_{user_id}", "données de test")
assert resultat is not None
except Exception as e:
erreurs.append(f"user_{user_id}: {e}")
with ThreadPoolExecutor(max_workers=50) as executor:
futures = [executor.submit(requete_utilisateur, i) for i in range(200)]
for f in futures:
f.result()
assert len(erreurs) == 0, f"Erreurs sous charge : {erreurs}"La règle que j’applique maintenant sur tous mes projets : aucun déploiement en production sans avoir fait tourner ces tests en staging au moins une fois dans les 24h précédentes.
Le même principe s’applique à ton copywriting : tester son texte en conditions réelles avant de le déployer en production. Lance un audit gratuit sur copyboost.io avant ta prochaine campagne.
Questions fréquentes
Qu’est-ce que le bug du London Ambulance Service de 1992 ?
En octobre 1992, le London Ambulance Service a déployé un nouveau logiciel de dispatch en production sans tests suffisants et sans staging équivalent à la charge réelle. Sous la charge de 2 500 appels quotidiens et avec des opérateurs mal formés, le système a saturé, généré des doublons, et s’est effondré. L’enquête officielle a conclu que le dysfonctionnement avait contribué à 20 à 30 morts supplémentaires pendant la semaine de crise.
Pourquoi un staging environment est-il nécessaire même pour un projet solo ?
Parce que ton environnement de développement local ne reproduit jamais les conditions réelles de production : charge utilisateur, données avec leurs cas limites et imperfections, interactions entre services en conditions réelles. Un staging environment minimal, identique en configuration à la production mais isolé, permet de détecter les bugs qui n’apparaissent que sous ces conditions avant qu’ils n’impactent les vrais utilisateurs.
Quelle est la différence entre un environnement de staging et de développement ?
L’environnement de développement est local, avec des données de test contrôlées et une charge minimale. L’environnement de staging est identique à la production en termes de configuration, de services, et idéalement de volume de données, mais isolé des utilisateurs réels. Les tests de charge, les tests avec des données de production anonymisées, et les tests d’intégration entre services tournent en staging, pas en développement.
Comment créer un staging minimal pour un projet Python en solo ?
Trois étapes suffisent pour commencer : séparer les variables d’environnement en fichiers .env.development, .env.staging, et .env.production, créer un script de déploiement qui exige APP_ENV=staging avant tout déploiement sur la branche principale, et écrire au moins 3 tests marqués skipif APP_ENV != staging qui couvrent la charge et les données réelles. Le reste s’affine avec l’expérience.
Comment planifier un rollback avant un déploiement ?
Avant chaque déploiement, documente en trois lignes : quelle est la version précédente stable, comment y revenir en moins de 5 minutes, et comment vérifier que le rollback a réussi. Sur Vercel, c’est un clic dans l’interface. Sur un VPS, c’est un script de restauration depuis un backup. L’important est de l’avoir testé avant d’en avoir besoin, pas pendant un incident.
Ship fast, mais pas comme ça
“Move fast and break things” est un principe qui a du sens dans un contexte de produit early stage sans utilisateurs critiques. Il n’en a aucun sur un système de dispatch d’ambulances.
Mais même sur un SaaS grand public, shipper sans staging est une décision qui finit par coûter cher. Pas en vies humaines comme au LAS. En utilisateurs perdus, en réputations abîmées, en nuits de debug passées à corriger en production ce qu’un test de charge de 30 minutes en staging aurait détecté.
Si je devais résumer ce que le LAS m’a appris en une règle : le staging n’est pas un luxe de grande équipe. C’est une condition préalable à tout déploiement sur lequel des gens dépendent.
Ship vite. Mais avec un filet.
Lance un audit gratuit sur copyboost.io avant ta prochaine campagne de lancement.
Dernière mise à jour : mai 2026
Cet article fait partie de la série 10 bugs informatiques qui ont tué, crashé et coûté des milliards.
Discussion