
- Le 19 juillet 2024, un fichier de config de 42 Ko mal validé a bloqué 8,5 millions de machines Windows en boucle de redémarrage.
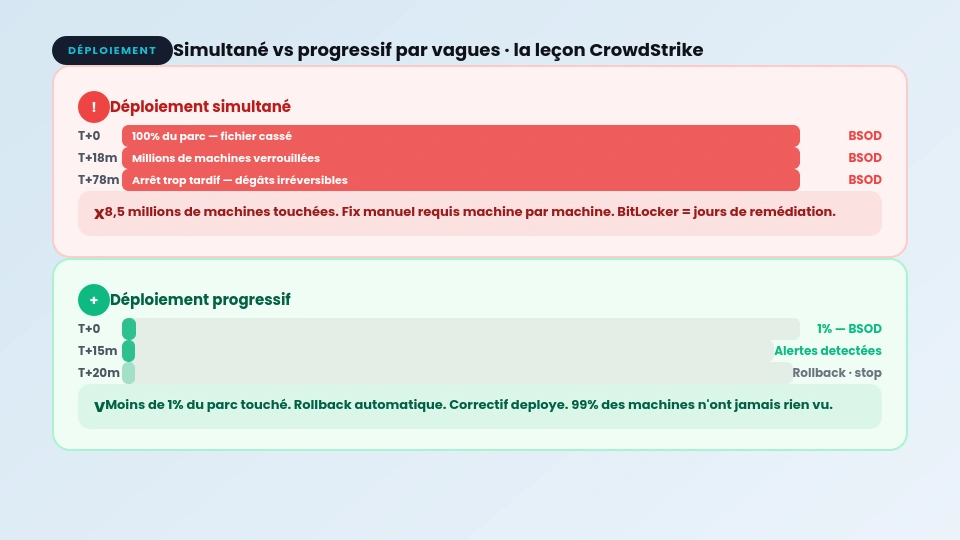
- Le déploiement simultané sur 100% du parc sans canary release a transformé un bug localisé en catastrophe mondiale.
- Coût estimé à 5,4 milliards de dollars pour les entreprises Fortune 500 en une seule matinée.
- Un déploiement progressif à 1% du parc avec surveillance des métriques aurait limité l'impact à quelques centaines de machines.
- Staging obligatoire, rollback testé et feature flags sur les fichiers de configuration sont non négociables pour tout déploiement critique.
Lecture complète : 13 min
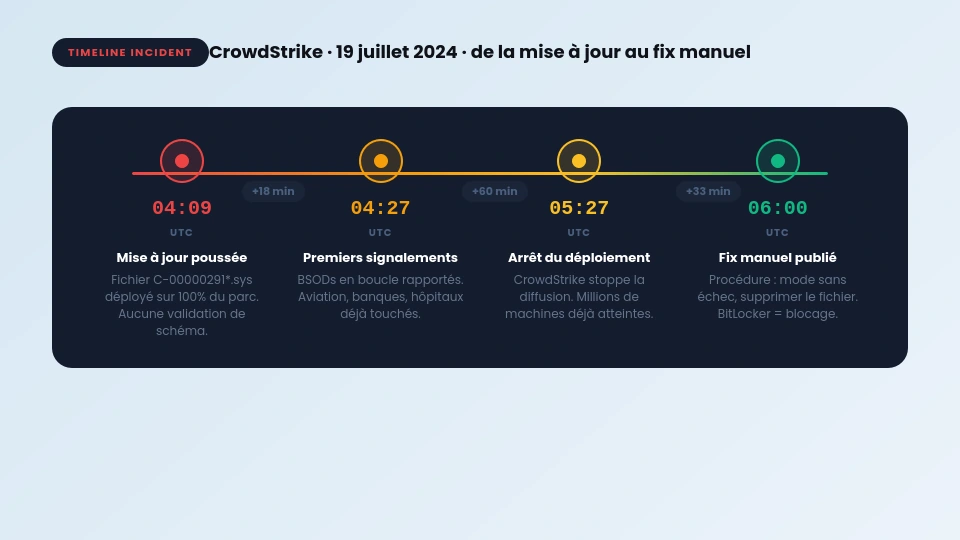
Le 19 juillet 2024, à 04h09 UTC, un fichier de 42 Ko a mis à genoux 8,5 millions de machines Windows.
Des aéroports ont cloué leurs avions au sol. Des hôpitaux ont annulé des opérations. Des banques ont gelé leurs transactions. Tout ça pour un fichier de configuration mal validé, poussé en prod sans filet. Pas un exploit de hackers. Pas une faille zero-day. Une mise à jour de routine qui n’aurait jamais dû passer en production dans cet état.
Ce qui s’est passé ce jour-là, c’est le cauchemar de tout dev qui déploie du code sans pipeline solide. Et si tu builds des produits en solo comme moi, il y a des leçons ici que tu ne peux pas te permettre d’ignorer.
Ce qui s’est passé : les faits bruts
CrowdStrike est un éditeur de logiciels de cybersécurité. Son produit phare, Falcon Sensor, tourne au niveau du kernel Windows pour détecter les menaces en temps réel. C’est un pilote système, pas une app lambda.
Le 19 juillet 2024, CrowdStrike a poussé une mise à jour de ses “Channel Files”, des fichiers de configuration qui dictent comment Falcon Sensor détecte certains comportements malveillants. Le fichier en question s’appelait C-00000291*.sys.
Le problème : ce fichier contenait des données mal formées. Quand Falcon Sensor l’a lu au démarrage, ça a provoqué une lecture mémoire hors limites. Windows, qui n’accepte pas qu’un pilote kernel corrompe la mémoire système, a immédiatement planté avec un BSOD.
Résultat : toute machine Windows qui a reçu cette mise à jour entre 04h09 et 05h27 UTC est entrée dans une boucle infinie de redémarrage. Impossible de booter normalement.
Delta, United Airlines, les hôpitaux NHS en Grande-Bretagne, la Bourse de Londres, la banque australienne CBA. La liste est longue.
Les pertes estimées dépassent 5,4 milliards de dollars pour les seules entreprises du Fortune 500.
Pourquoi la mise à jour a provoqué un BSOD ?
La réponse directe : Falcon Sensor fonctionne en mode kernel, le niveau de privilège le plus élevé de Windows. Quand un pilote kernel accède à une adresse mémoire invalide, Windows ne peut pas récupérer l’erreur proprement. Il plante. Le fichier de configuration mal formé a déclenché exactement ce type d’accès invalide dès le démarrage du service.
Pour mettre ça en perspective avec du code : imagine un script Python qui lit un fichier CSV structuré. Si le fichier contient une colonne de moins que prévu, et que ton code essaie d’accéder à row[5] sur une ligne qui n’en a que 4, tu obtiens une IndexError.
import csv
def process_config(filepath):
with open(filepath, 'r') as f:
reader = csv.reader(f)
for row in reader:
# Si row[5] n'existe pas, IndexError
value = row[5]
process_value(value)En Python, cette erreur est récupérable. Tu ajoutes un try/except, tu logs l’erreur, tu continues.
En mode kernel Windows, la même logique produit un écran bleu. Il n’y a pas de try/except au niveau du hardware.
def process_config_safe(filepath):
with open(filepath, 'r') as f:
reader = csv.reader(f)
for i, row in enumerate(reader):
if len(row) < 6:
print(f"Ligne {i} invalide : {len(row)} colonnes attendues, 6 requises")
continue
value = row[5]
process_value(value)CrowdStrike n’avait pas de validation équivalente sur ce fichier de configuration. Ou si elle existait, elle n’a pas détecté le problème avant production.
L’erreur réelle : pas le code, le processus
Beaucoup de gens ont conclu que CrowdStrike avait “écrit du mauvais code”. C’est réducteur.
Le vrai problème, c’est l’absence de garde-fous dans le pipeline de déploiement. Quelques éléments qui ressortent du rapport post-mortem publié par CrowdStrike :
- Pas de validation de schéma sur les Channel Files avant déploiement
- Déploiement simultané sur 100 % du parc client, sans déploiement progressif
- Absence de canary release ou de rollout par vagues
- Temps de détection trop lent pour stopper le déploiement en cours
Sur ce dernier point : entre la mise à jour et la détection publique du problème, il s’est écoulé plus d’une heure. Une heure pendant laquelle des millions de machines ont reçu le fichier cassé.
Si CrowdStrike avait déployé sur 1 % des machines d’abord, attendu 15 minutes, et surveillé les métriques de crash, la panne se serait limitée à une fraction du parc. Les équipes auraient rollbacké, corrigé, et la plupart des utilisateurs n’auraient jamais rien vu.
Ce que j’ai changé dans mon propre pipeline après ça
Je builds en solo. Mon “parc client” sur Copyboost, c’est quelques dizaines d’utilisateurs, pas 8,5 millions de machines. Mais la leçon s’applique à toute échelle.
Avant cet incident, mon workflow de déploiement sur Vercel ressemblait à ça :
- Push sur
main - Vercel build automatique
- Déploiement en prod direct
Après ? J’ai ajouté trois choses.
Des tests de validation avant chaque merge. Pas des tests unitaires exhaustifs parce que je n’ai pas le temps. Mais au moins un test de smoke : l’app démarre, les routes principales répondent, les appels API Anthropic fonctionnent.
Un environnement de staging séparé. Chaque PR part d’abord sur un environnement preview Vercel. Je le teste manuellement pendant 10 minutes avant de merger sur main. J’en parle dans mon article sur les erreurs Python sur VPS qui m’ont coûté des heures : la majorité de mes bugs auraient été détectés avec 10 minutes de test en staging.
Un rollback en un clic. Vercel permet de revenir instantanément à un déploiement précédent. J’ai vérifié que je savais exactement où cliquer avant d’en avoir besoin. Comme les issues de sécurité : tu prépares le plan de secours quand tout va bien, pas quand tout brûle.
Feature flags et déploiement progressif : la technique qui aurait tout évité
Un feature flag est un interrupteur dans ton code qui permet d’activer ou désactiver une fonctionnalité sans déployer de nouveau code. Le déploiement progressif consiste à activer ce flag pour un pourcentage croissant d’utilisateurs, en surveillant les métriques à chaque palier avant de passer au suivant.
Voici une implémentation minimaliste en Python :
import hashlib
FEATURE_FLAGS = {
"new_config_parser": 0.05, # Actif pour 5 % des users
}
def is_feature_enabled(feature_name: str, user_id: str) -> bool:
if feature_name not in FEATURE_FLAGS:
return False
rollout_percentage = FEATURE_FLAGS[feature_name]
# Hash déterministe : même user_id = même résultat à chaque appel
hash_value = int(hashlib.md5(f"{feature_name}:{user_id}".encode()).hexdigest(), 16)
user_bucket = (hash_value % 100) / 100.0
return user_bucket < rollout_percentage
# Utilisation
def parse_config(config_data: dict, user_id: str):
if is_feature_enabled("new_config_parser", user_id):
return new_parser(config_data)
return legacy_parser(config_data)Avec ce système, CrowdStrike aurait pu déployer le fichier cassé sur 1 % de ses clients. Les crashs auraient été détectés en quelques minutes. Le flag aurait été coupé, et 99 % du parc n’aurait jamais été touché.
Pour des projets solo, des outils comme PostHog ou Unleash offrent ça clés en main. L’implémentation maison ci-dessus suffit pour commencer.
Stratégie de rollback : anticiper avant de déployer
Le rollback, c’est la capacité à revenir à la version précédente rapidement. Trois règles simples :
- Documente ta procédure de rollback avant de déployer. Si tu dois la chercher sous pression, c’est déjà trop tard.
- Teste ton rollback en conditions réelles. Un rollback que tu n’as jamais exécuté ne vaut rien.
- Versionne tes fichiers de configuration comme ton code. CrowdStrike gérait ses Channel Files en dehors de son pipeline de versioning habituel. C’est précisément là que la validation a sauté.
En pratique sur un projet Next.js/Vercel :
# Lister les déploiements récents
vercel ls
# Promouvoir un déploiement précédent en production
vercel alias set monapp-abc123.vercel.app monapp.comSur un VPS classique avec Python, tu veux a minima ça :
import subprocess
import datetime
def deploy_with_rollback(new_version: str, current_version: str):
backup_path = f"/opt/myapp/backups/{current_version}_{datetime.date.today()}"
# Backup de la version courante
subprocess.run(["cp", "-r", "/opt/myapp/current", backup_path], check=True)
# Déploiement de la nouvelle version
try:
subprocess.run(["./deploy.sh", new_version], check=True, timeout=120)
print(f"Déploiement {new_version} réussi")
except subprocess.CalledProcessError:
print("Déploiement échoué, rollback en cours...")
subprocess.run(["cp", "-r", backup_path, "/opt/myapp/current"], check=True)
subprocess.run(["systemctl", "restart", "myapp"], check=True)
print(f"Rollback vers {current_version} effectué")Checklist avant tout déploiement en prod :
- Environnement de staging testé
- Procédure de rollback documentée et testée
- Métriques de surveillance configurées
- Feature flag prêt si la fonctionnalité est risquée
- Déploiement progressif si la surface impactée est large
Questions fréquentes
Qu’est-ce que le bug CrowdStrike de 2024 exactement ?
Le 19 juillet 2024, CrowdStrike a poussé une mise à jour défectueuse de ses fichiers de configuration pour son logiciel Falcon Sensor. Cette mise à jour a provoqué un accès mémoire invalide au niveau du kernel Windows, causant un écran bleu de la mort sur environ 8,5 millions de machines dans le monde. Les secteurs les plus touchés : aviation, santé, finance et télécommunications.
Pourquoi le problème a-t-il touché autant de machines en si peu de temps ?
CrowdStrike a déployé la mise à jour simultanément sur l’ensemble de son parc client, sans déploiement progressif. Il n’y avait pas de mécanisme de rollout par vagues permettant de détecter les crashs sur un échantillon avant d’élargir. Une fois la mise à jour partie, elle a atteint des millions de machines en moins d’une heure.
Comment fixer une machine bloquée en BSOD après la panne CrowdStrike ?
La solution recommandée par CrowdStrike était de démarrer en mode sans échec Windows, puis de supprimer manuellement le fichier C-00000291*.sys dans le dossier C:\Windows\System32\drivers\CrowdStrike\. Pour les machines chiffrées avec BitLocker, il fallait d’abord récupérer la clé de récupération, ce qui a considérablement ralenti la remédiation dans les grandes entreprises.
Un projet solo a-t-il besoin d’un pipeline CI/CD complet ?
Pas forcément un pipeline complet. Mais trois éléments sont non négociables quelle que soit la taille du projet : un environnement de staging séparé de la prod, une procédure de rollback documentée et testée, et une validation automatique basique avant tout déploiement. Le coût de mise en place est de quelques heures. Le coût d’un déploiement cassé sans filet peut dépasser des jours de travail.
Qu’est-ce qu’un feature flag et comment ça prévient ce type de panne ?
Un feature flag est un interrupteur conditionnel dans le code qui permet d’activer une fonctionnalité pour un sous-ensemble d’utilisateurs. En déployant une mise à jour à 1 ou 5 % du parc d’abord, puis en surveillant les métriques avant d’élargir, on limite l’impact d’un bug à une fraction des utilisateurs. CrowdStrike n’utilisait pas ce mécanisme pour ses fichiers de configuration, ce qui explique l’ampleur globale de la panne.
Ce que tu retiens de tout ça
CrowdStrike n’a pas écrit du mauvais code. CrowdStrike a déployé sans filet.
La différence est importante. Un bug dans du code, ça arrive à tout le monde. Un pipeline sans rollback, sans déploiement progressif, sans validation des fichiers de configuration : c’est un choix. Un choix qui, à grande échelle, a coûté plus de 5 milliards de dollars en une matinée.
Ce que j’ai retenu : staging obligatoire, rollback testé, feature flags sur tout ce qui touche des données de configuration. Pas parce que je déploie sur 8,5 millions de machines. Parce que mes utilisateurs méritent la même rigueur, à mon échelle.
Teste le texte de ta prochaine mise à jour produit avec le Diagnostic de Performance sur copyboost.io. Gratuit, 30 secondes.
Dernière mise à jour : mai 2026
Cet article fait partie de la série 10 bugs informatiques qui ont tué, crashé et coûté des milliards.
Discussion