
- Les killer typos produisent des programmes syntaxiquement valides mais sémantiquement incorrects, sans aucune erreur visible à l'exécution.
- Le Mariner 1 a explosé en 1962 à cause d'une barre de fraction manquante dans une formule de guidance (18,5 millions de dollars).
- Le cerveau humain lit par anticipation et rate les typos dans le code familier : les linters, non.
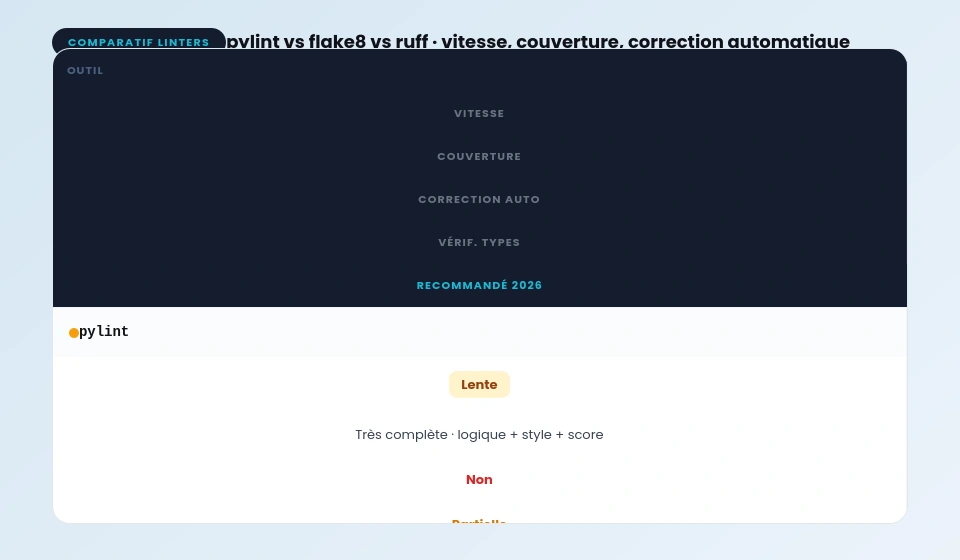
- ruff est 10 à 100 fois plus rapide que pylint ou flake8 et supporte la correction automatique.
- Un pipeline CI avec ruff, mypy et pylint (seuil 8.0) bloque les typos avant le merge en moins de 30 secondes.
Lecture complète : 13 min
Une seule lettre. Parfois même un seul caractère.
C’est souvent tout ce qui sépare un programme qui fonctionne d’un programme qui cause des millions de dollars de dégâts. L’histoire de l’informatique est ponctuée de bugs causés non pas par une logique incorrecte mais par une frappe incorrecte, une variable mal nommée, un opérateur confondu.
Les “killer typos” sont la catégorie de bugs la plus humiliante. Pas de race condition complexe, pas d’algorithme défaillant. Une lettre dans le mauvais ordre, un = là où il faut ==, un nom de variable qui ressemble à un autre.
Et des conséquences parfois disproportionnées.
Les killer typos les plus coûteux de l’histoire
Un killer typo est une erreur de frappe dans du code source qui produit un programme syntaxiquement valide mais sémantiquement incorrect. Ces bugs sont particulièrement dangereux parce qu’ils ne génèrent pas d’erreur à la compilation ou à l’exécution : le programme tourne, mais fait autre chose que ce qui était prévu.
Le Mariner 1, 1962. Une barre de fraction manquante dans une formule de guidance a envoyé la sonde spatiale sur une trajectoire incorrecte. La NASA a détruit la sonde 293 secondes après le lancement. Coût : 18,5 millions de dollars.
# Ce que le code faisait (simplifié)
def calculer_correction_trajectoire_bugguee(R, valeur_actuelle, valeur_precedente):
return R + valeur_actuelle # Typo : opération incorrecte
# Ce que le code aurait dû faire
def calculer_correction_trajectoire_correcte(R, valeur_actuelle, valeur_precedente):
R_dot = valeur_actuelle - valeur_precedente
return R + R_dotLe Flash Crash de 2010. Un trader a saisi 16 milliards de dollars au lieu de 16 millions dans un ordre de vente. Le marché a perdu 1 000 points en quelques minutes. Les algorithmes de trading automatique ont amplifié le mouvement. Mille milliards de dollars de capitalisation boursière ont disparu le temps que les échanges soient annulés.
La faille OpenSSL Heartbleed, 2014. Techniquement plus qu’un typo, mais à l’origine : une variable de longueur non validée dans le code du protocole Heartbeat. Le développeur n’a pas vérifié que la longueur du message déclarée correspondait à la longueur réelle. Un linter avec des règles de validation aurait détecté ce chemin de code non validé.
Le déploiement AWS us-east-1, 2017. Un ingénieur AWS exécutait une commande pour retirer un petit nombre de serveurs du service S3. Il a saisi un argument incorrect et a retiré beaucoup plus de serveurs que prévu. Le résultat : une panne de plusieurs heures qui a mis hors ligne une fraction significative d’internet.
La faute de frappe diplomatique
Le cas le plus célèbre de typo à conséquences potentiellement catastrophiques est le faux alerte nucléaire soviétique de 1983.
Le 26 septembre 1983, le système d’alerte précoce soviétique a détecté ce qu’il interprétait comme le lancement de cinq missiles balistiques intercontinentaux américains.
L’officier de service cette nuit-là, le lieutenant-colonel Stanislav Petrov, avait deux options : suivre le protocole et alerter la chaîne de commandement, déclenchant potentiellement une riposte nucléaire, ou classifier l’alerte comme une fausse alarme en prenant sur lui toute la responsabilité.
Il a choisi la deuxième option. Il a eu raison.
Ce n’était pas à proprement parler un typo dans du code. C’était une erreur de conception dans l’algorithme de classification des satellites qui confondait le reflet du soleil sur des nuages à haute altitude avec des jets de propulseur de missile.
Mais la leçon de code est identique : un algorithme de classification qui ne gère pas les cas limites de son entrée peut produire des résultats catastrophiquement incorrects avec une confiance élevée.
def classifier_signature_infrarouge_bugguee(intensite: float, angle_soleil: float) -> str:
"""Classification simpliste sans gestion des cas limites."""
if intensite > 0.85:
return "MISSILE" # Faux positif si angle_soleil élevé + nuages
return "INOFFENSIF"
def classifier_signature_infrarouge_correcte(
intensite: float,
angle_soleil: float,
couverture_nuageuse: float,
nb_sources_detectees: int
) -> tuple[str, float]:
"""Classification avec gestion des cas limites et score de confiance."""
score_missile = 0.0
score_missile += intensite * 0.4
# Correction pour les conditions de réflexion solaire
if angle_soleil > 60 and couverture_nuageuse > 0.5:
score_missile *= 0.3
if nb_sources_detectees < 3:
score_missile *= 0.2
classification = "MISSILE" if score_missile > 0.7 else "INOFFENSIF"
if 0.4 < score_missile < 0.7:
classification = "AMBIGU_VERIFICATION_REQUISE"
return classification, round(score_missile, 3)
print(classifier_signature_infrarouge_bugguee(0.9, 75)) # MISSILE (faux positif)
print(classifier_signature_infrarouge_correcte(0.9, 75, 0.8, 1))Pourquoi les typos passent inaperçus dans les revues humaines
Le cerveau humain lit ce qu’il s’attend à lire, pas ce qui est écrit. C’est un mécanisme cognitif documenté : quand tu lis du code que tu connais bien, ton cerveau prédit le prochain mot ou symbole et saute la vérification visuelle détaillée.
def calculer_remise(prix: float, taux_remise: float) -> float:
if taux_remise < 0 or taux_remise > 1:
raise ValueError("Taux de remise invalide")
prix_reduit = prix * (1 - taux_remise)
economie = prix - prix_reduit
# Le bug est ici. Tu le vois ?
return prix_reduit + economie # Retourne le prix original, pas le prix réduitC’est pour ça que les revues de code humaines capturent mal les typos. Un second regard humain tombe dans le même piège cognitif que le premier. Les linters, eux, ne lisent pas par anticipation. Ils analysent le code tel qu’il est écrit.
Code review : comment l’organiser pour capturer les typos
La code review ne devrait pas chercher les typos. C’est le travail des linters automatiques. La code review devrait se concentrer sur la logique, l’architecture, les cas limites non gérés, et la lisibilité. En séparant ces deux responsabilités, tu libères l’attention humaine pour ce que les machines font mal, et tu délègues aux machines ce qu’elles font mieux.
Checklist de code review efficace :
## Revue automatique (linter, avant tout review humain)
- [ ] pylint ou ruff passe sans erreur
- [ ] mypy passe sans erreur en mode strict
- [ ] Les tests passent en CI
## Revue humaine (uniquement après la revue automatique)
- [ ] La logique est correcte pour les cas normaux
- [ ] Les cas limites sont gérés (valeurs nulles, vides, négatives, très grandes)
- [ ] Les erreurs sont traitées explicitement, pas silencieusement
- [ ] Les noms de variables et fonctions décrivent leur intention
- [ ] Le code peut être compris par quelqu'un qui ne l'a pas écritLinters Python : pylint, flake8 et ruff en pratique
Trois outils principaux, avec des forces différentes.
pylint : l’analyse la plus complète
pip install pylint
pylint mon_module.pydef calcul(x, y, z): # pylint: C0116 missing-function-docstring
result = x + y # pylint: W0612 unused-variable
if x == True: # pylint: C0121 singleton-comparison
return z
retun x + z # pylint: E0001 syntax-error (faute : retun vs return)pylint attribue un score de 0 à 10 à ton code. L’objectif : maintenir un score au-dessus de 8.0 sur tous les modules.
flake8 : rapide, minimaliste, idéal pour le CI
pip install flake8
flake8 mon_module.py --max-line-length=88flake8 se concentre sur le style PEP 8 et les erreurs syntaxiques. Plus rapide que pylint, idéal comme premier gate dans un pipeline CI.
ruff : le remplaçant moderne, 10 à 100x plus rapide
pip install ruff
ruff check mon_module.py
ruff check --fix mon_module.py # Correction automatique quand possibleruff réimplémente pylint, flake8, isort et d’autres outils en Rust. Il tourne en quelques millisecondes même sur de gros projets. C’est l’outil que j’utilise maintenant sur Copyboost.
Configuration dans pyproject.toml
[tool.ruff]
line-length = 88
select = [
"E", # pycodestyle errors
"F", # pyflakes
"W", # pycodestyle warnings
"N", # pep8-naming
"UP", # pyupgrade
"B", # flake8-bugbear
"SIM", # flake8-simplify
]
ignore = ["E501"]
[tool.pylint.messages_control]
disable = ["C0114", "C0115"]
[tool.mypy]
python_version = "3.11"
strict = true
warn_return_any = trueIntégration dans le pipeline CI (GitHub Actions)
# .github/workflows/quality.yml
name: Code Quality
on: [push, pull_request]
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Installer les outils
run: pip install ruff mypy pylint
- name: Ruff
run: ruff check . --output-format=github
- name: mypy
run: mypy . --strict
- name: pylint
run: pylint src/ --fail-under=8.0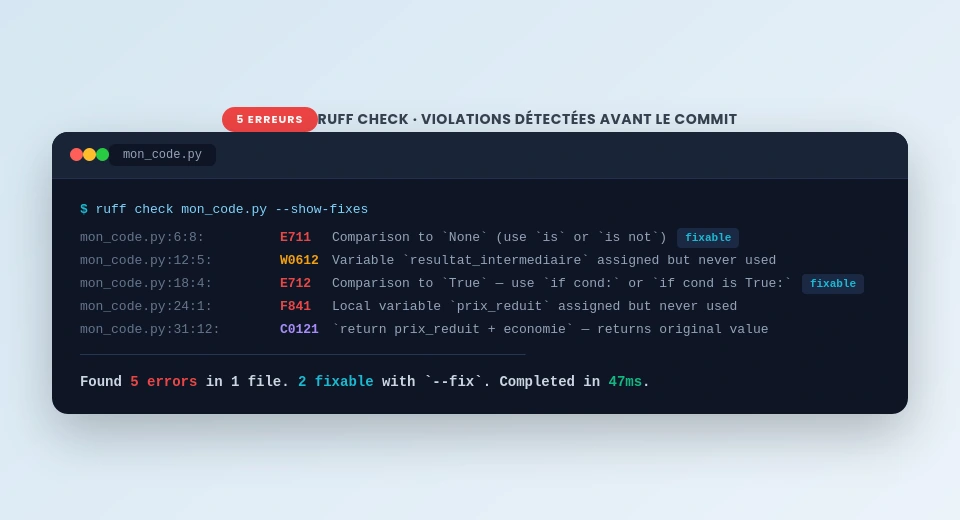
Ce pipeline bloque tout push qui introduit des erreurs de typo, des incohérences de type, ou un score pylint trop bas. Il tourne en moins de 30 secondes sur un projet de taille moyenne.
Questions fréquentes
Qu’est-ce qu’un killer typo en programmation ?
Un killer typo est une erreur de frappe dans du code source qui produit un programme syntaxiquement valide mais au comportement incorrect. Contrairement aux erreurs de syntaxe, les killer typos ne génèrent pas de message d’erreur à la compilation : le programme s’exécute, mais fait autre chose que prévu. Les exemples incluent un = au lieu de ==, un nom de variable presque identique à un autre, ou un opérateur manquant qui change complètement le calcul.
Pourquoi les code reviews humaines ne capturent-elles pas les typos ?
Le cerveau humain lit par anticipation : il prédit la suite d’un texte connu et réduit son attention visuelle sur les détails. Dans du code familier, un reviewer lit ce qu’il s’attend à voir plutôt que ce qui est écrit. Les linters, eux, analysent chaque token indépendamment sans biais de lecture. La division du travail optimale : linters pour les typos et le style, humains pour la logique et l’architecture.
Quelle est la différence entre pylint, flake8 et ruff ?
flake8 est rapide et minimaliste, centré sur le style PEP 8 et les erreurs syntaxiques. pylint est plus complet et analyse la logique, les imports, les variables inutilisées, et donne un score global. ruff réimplémente les deux en Rust, est 10 à 100 fois plus rapide, et supporte la correction automatique. Pour un nouveau projet en 2026, ruff + mypy couvre la grande majorité des cas.
Comment intégrer un linter dans un projet Python existant ?
Lance d’abord ruff check . --statistics pour avoir une vue d’ensemble des violations sans bloquer. Règle les erreurs critiques (E et F) en premier. Ajoute ruff en pre-commit hook pour que les vérifications tournent avant chaque commit. Pour les projets avec beaucoup de violations existantes, corrige progressivement par module.
Le pair programming évite-t-il vraiment les typos ?
Le pair programming réduit les typos qui passent inaperçus, mais ne les élimine pas : deux personnes peuvent tomber dans le même biais de lecture. Son vrai avantage est sur la logique et les cas limites, pas sur les fautes de frappe. La combinaison optimale est : linter automatique pour les typos, pair programming ou code review pour la logique, tests automatisés pour les comportements attendus.
Les meilleurs outils ne remplacent pas l’attention
Le Mariner 1 a explosé en 1962 parce qu’une barre de fraction manquait dans une formule. Les linters de l’époque n’existaient pas.
Aujourd’hui, ruff détecte en 50 millisecondes des centaines de patterns qui causent des bugs. mypy vérifie les types avant l’exécution. GitHub Actions bloque les merges qui introduisent des erreurs de style.
Ces outils sont disponibles, gratuits, et s’installent en cinq minutes. Ne pas les utiliser en 2026, c’est faire le choix de laisser des bugs qui auraient pu être évités automatiquement.
Ce que j’ai mis en place sur Copyboost :
- ruff en pre-commit hook : bloque le commit si une erreur est détectée.
- mypy en CI : bloque le merge si les types ne passent pas.
- pylint avec un seuil de 8.0 minimum : refus de déployer en dessous.
Ca n’a pas rendu mon code parfait. Ca a juste éliminé la catégorie entière de bugs qui n’auraient pas dû exister.
Applique le même niveau de rigueur à ton copywriting. Lance un audit gratuit sur copyboost.io pour détecter ce qui coince avant de publier.
Dernière mise à jour : mai 2026
Cet article fait partie de la série 10 bugs informatiques qui ont tué, crashé et coûté des milliards.
Discussion