
- Le 14 août 2003, une race condition dans le logiciel XA/21 de FirstEnergy a déclenché la plus grande panne électrique nord-américaine (55 millions de personnes).
- XA/21 a continué d'afficher une interface normale pendant 2 heures sans envoyer aucune alerte, c'est le scénario de failure silencieuse le plus dangereux.
- Une race condition nécessite 2 threads, au moins une écriture partagée et une absence de synchronisation pour se produire.
- queue.Queue est thread-safe en Python contrairement aux listes brutes partagées entre threads.
- Un watchdog qui surveille l'activité d'un système critique est la seule protection fiable contre les failures silencieuses.
Lecture complète : 13 min
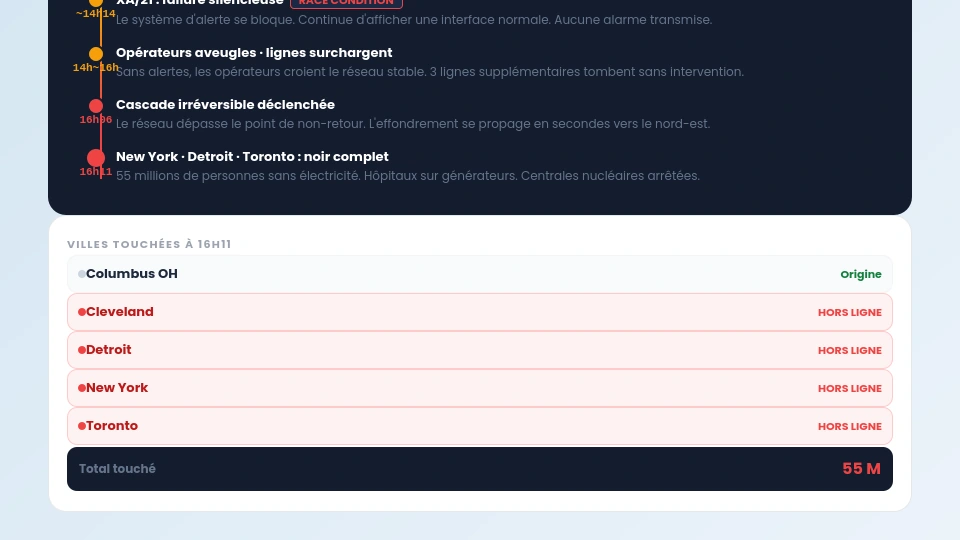
Le 14 août 2003 à 16h06, l’électricité a disparu pour 55 millions de personnes aux États-Unis et au Canada.
New York, Detroit, Cleveland, Toronto. Des hôpitaux sur générateurs. Des gens bloqués dans des ascenseurs. Des centrales nucléaires arrêtées en urgence. La plus grande panne électrique de l’histoire nord-américaine.
La cause officielle : une série d’erreurs humaines et techniques en cascade. Mais au coeur de la cascade, il y avait un logiciel. Un système de surveillance du réseau électrique de FirstEnergy dans l’Ohio qui avait cessé d’alerter les opérateurs, sans leur dire qu’il avait cessé d’alerter.
Ce logiciel avait une race condition.
Comment une panne locale en Ohio a éteint le nord-est du continent
Les réseaux électriques fonctionnent comme des systèmes d’équilibre dynamique. La production doit correspondre à la consommation en temps réel. Quand une ligne tombe, le courant se redistribue sur les lignes voisines. Si elles surchargent à leur tour, elles tombent aussi. Une cascade peut se produire.
Le 14 août 2003, vers 14h, une ligne de FirstEnergy dans l’Ohio est tombée en contact avec un arbre mal taillé. Incident banal, récupérable. Mais les opérateurs de FirstEnergy n’ont pas été alertés. Leur système de surveillance, XA/21, avait cessé de fonctionner correctement sans afficher d’erreur visible.
Pendant deux heures, les opérateurs ont cru que leur réseau était stable. Pendant ces deux heures, d’autres lignes ont surchargé et sont tombées, une par une. À 16h06, la situation était devenue irrécupérable. Le réseau s’est effondré en cascade sur l’ensemble du nord-est.
Le rapport de la commission d’enquête américano-canadienne, publié en 2004, identifie explicitement la défaillance du système XA/21 comme l’un des facteurs déclencheurs. Sans cette défaillance, les opérateurs auraient eu le temps d’intervenir.
Le bug XA/21 : ce qui s’est passé dans le logiciel
Le système XA/21 utilisait un mécanisme d’alerte pour notifier les opérateurs quand une ligne du réseau tombait. Ce mécanisme avait une race condition : deux processus accédaient simultanément à la même structure de données partagée sans synchronisation correcte. Quand les deux processus se sont exécutés en même temps dans un certain ordre, le système d’alerte s’est bloqué. XA/21 continuait de s’exécuter, affichant une interface normale, mais ne transmettait plus aucune alarme.
C’est le détail qui rend ce bug particulièrement vicieux : le système n’a pas planté. Il n’a pas affiché d’erreur. Il a continué de sembler fonctionner normalement. Les opérateurs n’avaient aucune raison de douter de leur outil.
Un logiciel qui tombe silencieusement sans le dire est souvent plus dangereux qu’un logiciel qui plante bruyamment.
Ce comportement a un nom : une failure silencieuse. Elle est beaucoup plus commune qu’on ne le croit, et le cas XA/21 en est l’illustration la plus coûteuse documentée.
Qu’est-ce qu’une race condition dans un système concurrent ?
Une race condition se produit quand le comportement d’un programme dépend de l’ordre d’exécution de plusieurs threads ou processus sur une ressource partagée, et que cet ordre n’est pas garanti. Le résultat est non-déterministe : le même code peut produire des résultats différents selon le timing exact de chaque exécution.
La difficulté : les race conditions sont souvent impossibles à reproduire de façon fiable en développement. Elles apparaissent sous charge, dans certaines configurations matérielles, ou à des moments spécifiques du cycle de vie du processus. Le bug XA/21 ne se déclenchait probablement pas sur les serveurs de test, où la charge était faible et les timings différents de ceux de production.
Trois conditions doivent être réunies pour qu’une race condition soit possible :
- Au moins deux threads accèdent à la même ressource partagée.
- Au moins un de ces accès est une écriture.
- Il n’y a pas de mécanisme de synchronisation pour ordonner ces accès.
Si l’une de ces trois conditions est absente, la race condition ne peut pas se produire.
Reproduire le bug en Python : deux threads, un fichier, un désastre
Voici une simulation simplifiée du type de bug qui a touché XA/21 : deux threads qui gèrent une file d’alertes partagée sans synchronisation.
import threading
import time
import random
file_alertes = []
alertes_traitees = 0
systeme_actif = True
def producteur_alertes(nom: str, nb_alertes: int):
"""Simule le processus qui détecte les anomalies et écrit les alertes."""
for i in range(nb_alertes):
time.sleep(random.uniform(0.001, 0.01))
alerte = {"id": f"{nom}_{i}", "niveau": "critique", "ligne": f"ligne_{i}"}
# PROBLÈME : lecture puis écriture non atomique
taille_actuelle = len(file_alertes)
time.sleep(0.0001) # Fenêtre de vulnérabilité
file_alertes.append(alerte)
def consommateur_alertes():
"""Simule le processus qui lit et affiche les alertes aux opérateurs."""
global alertes_traitees, systeme_actif
while systeme_actif or file_alertes:
if file_alertes:
try:
alerte = file_alertes.pop(0)
alertes_traitees += 1
except IndexError:
# Race condition silencieuse : la liste était vide entre le if et le pop
pass
time.sleep(0.001)
threads = [
threading.Thread(target=producteur_alertes, args=("capteur_A", 50)),
threading.Thread(target=producteur_alertes, args=("capteur_B", 50)),
threading.Thread(target=consommateur_alertes),
]
for t in threads:
t.start()
time.sleep(0.5)
systeme_actif = False
for t in threads:
t.join()
print(f"Alertes attendues : 100")
print(f"Alertes traitées : {alertes_traitees}")
print(f"Alertes perdues : {100 - alertes_traitees}")
# Résultat variable : entre 5 et 30 alertes peuvent être perdues sans erreurLance ce code plusieurs fois. Le nombre d’alertes perdues change à chaque exécution. Parfois 3, parfois 25. Le système continue de tourner, affichant un comportement “normal”, pendant que des alertes disparaissent silencieusement.
C’est précisément ce qui s’est passé avec XA/21 le 14 août 2003.
Comment protéger un système concurrent en Python
Deux outils principaux : threading.Lock pour les sections critiques, et queue.Queue pour les files de données partagées entre threads.
Correction avec queue.Queue : la solution propre
import threading
import queue
import time
import random
file_alertes = queue.Queue()
alertes_traitees = 0
systeme_actif = True
lock_compteur = threading.Lock()
def producteur_alertes_safe(nom: str, nb_alertes: int):
"""Version sécurisée : queue.Queue gère la synchronisation."""
for i in range(nb_alertes):
time.sleep(random.uniform(0.001, 0.01))
alerte = {"id": f"{nom}_{i}", "niveau": "critique", "ligne": f"ligne_{i}"}
file_alertes.put(alerte) # Thread-safe, pas de race condition possible
def consommateur_alertes_safe():
"""Version sécurisée : get() avec timeout pour éviter le blocage infini."""
global alertes_traitees, systeme_actif
while systeme_actif or not file_alertes.empty():
try:
alerte = file_alertes.get(timeout=0.1)
with lock_compteur:
alertes_traitees += 1
file_alertes.task_done()
except queue.Empty:
continue
threads = [
threading.Thread(target=producteur_alertes_safe, args=("capteur_A", 50)),
threading.Thread(target=producteur_alertes_safe, args=("capteur_B", 50)),
threading.Thread(target=consommateur_alertes_safe),
]
for t in threads:
t.start()
time.sleep(0.5)
systeme_actif = False
for t in threads:
t.join()
print(f"Alertes attendues : 100")
print(f"Alertes traitées : {alertes_traitees}")
print(f"Alertes perdues : {100 - alertes_traitees}")
# Résultat constant : 0 alerte perdue, à chaque exécution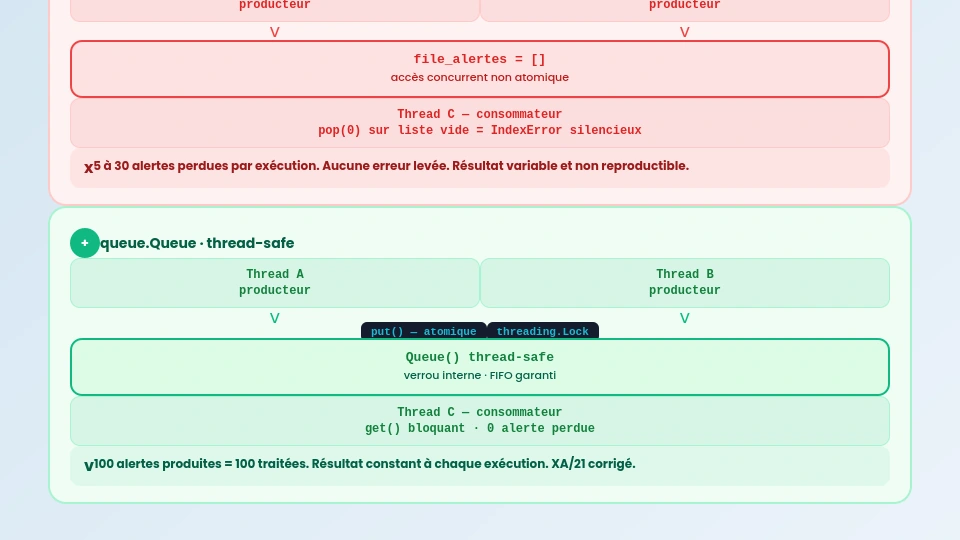
Deuxième principe : les failures silencieuses doivent être interdites
Le bug XA/21 était double : la race condition ET l’absence de détection que le système d’alerte ne fonctionnait plus. Un watchdog simple aurait suffi.
import threading
import time
class WatchdogAlerte:
"""Surveille l'activité d'un système et lève une alarme si il devient silencieux."""
def __init__(self, timeout_secondes: int = 30):
self.timeout = timeout_secondes
self.derniere_activite = time.time()
self._lock = threading.Lock()
self._actif = True
def signal_activite(self):
with self._lock:
self.derniere_activite = time.time()
def surveiller(self):
while self._actif:
with self._lock:
inactivite = time.time() - self.derniere_activite
if inactivite > self.timeout:
self._alarme_silence(inactivite)
time.sleep(5)
def _alarme_silence(self, duree: float):
"""Alerte explicite quand le système devient silencieux."""
print(f"ALARME WATCHDOG : aucune activité depuis {duree:.0f} secondes")
print("Le système de surveillance est peut-être défaillant")
def arreter(self):
self._actif = FalseSi XA/21 avait eu un watchdog de ce type, les opérateurs auraient su que leur système de surveillance était silencieux depuis plusieurs minutes. Ils auraient eu le temps d’agir avant la cascade.
J’applique ce principe sur les agents Python de ma stack VPS pour Copyboost : chaque agent loggue son activité toutes les 5 minutes. Si le log s’arrête, c’est une alerte. J’en parle dans mon article sur les 5 erreurs Python sur VPS qui m’ont coûté des heures.
Questions fréquentes
Quelle était la cause réelle de la panne électrique de 2003 ?
La commission d’enquête américano-canadienne a identifié plusieurs causes combinées : des lignes non entretenues en Ohio, des erreurs humaines de FirstEnergy, et la défaillance silencieuse du logiciel de surveillance XA/21 qui empêchait les opérateurs d’être alertés des incidents en cours. Sans la défaillance de XA/21, les opérateurs auraient probablement pu intervenir avant que la situation ne devienne incontrôlable.
Qu’est-ce qu’une race condition en Python avec le module threading ?
Une race condition en Python threading se produit quand deux threads modifient une ressource partagée sans synchronisation. Python possède un GIL qui limite l’exécution parallèle du bytecode, mais il ne protège pas contre les race conditions sur des opérations composées : lire une valeur, la modifier, et l’écrire en trois instructions séparées reste exposé même avec le GIL actif.
queue.Queue est-il vraiment thread-safe en Python ?
Oui. queue.Queue utilise en interne des verrous (threading.Lock) pour garantir que toutes ses opérations sont atomiques. put(), get(), empty(), et qsize() sont toutes thread-safe. C’est la solution recommandée pour passer des données entre threads en Python, et c’est précisément le type de structure qui aurait protégé le système XA/21.
Comment détecter une race condition dans du code Python existant ?
Les race conditions sont difficiles à détecter par analyse statique. L’approche la plus efficace combine des tests de stress à haute concurrence avec concurrent.futures.ThreadPoolExecutor, le fuzzing des timings avec des time.sleep() délibérés dans les sections critiques pour agrandir les fenêtres de vulnérabilité, et l’outil ThreadSanitizer pour les extensions C. Le symptôme le plus commun : des résultats qui varient entre deux exécutions identiques.
Qu’est-ce qu’une failure silencieuse et pourquoi est-elle dangereuse ?
Une failure silencieuse se produit quand un système cesse de fonctionner correctement sans afficher d’erreur visible. Le système continue de sembler actif, mais ses fonctions critiques sont dégradées ou inactives. C’est plus dangereux qu’un crash explicite parce que les opérateurs ou développeurs ne savent pas qu’un problème existe. La solution est un watchdog : un processus indépendant qui surveille l’activité du système principal et alerte si il devient silencieux.
Ce que la panne de 2003 change à ta façon de gérer les threads
Le bug XA/21 n’était pas visible en développement. Il ne plantait pas proprement. Il continuait de tourner en silence pendant que le réseau électrique s’effondrait.
C’est la leçon la plus importante : un système qui tombe en silence est plus dangereux qu’un système qui plante.
Trois règles à appliquer immédiatement sur tout code concurrent :
- Ne jamais utiliser une liste ou un dictionnaire Python brut comme file partagée entre threads. Utilise
queue.Queue. - Protéger chaque variable partagée avec
threading.Lockdès qu’elle est modifiée dans plus d’un thread. - Ajouter un watchdog sur tout système qui doit produire de l’activité régulière. Un système silencieux doit alerter, pas se taire.
Un bug qui échoue bruyamment se corrige en quelques heures. Un bug qui échoue silencieusement peut tourner en production pendant des semaines avant qu’on comprenne ce qui s’est passé.
Lance un audit gratuit sur copyboost.io : ton copywriting mérite le même niveau d’attention que ton code.
Dernière mise à jour : mai 2026
Cet article fait partie de la série 10 bugs informatiques qui ont tué, crashé et coûté des milliards.
Discussion